OpenCL 3.0, the new specifications for heterogeneous calculation are now ready
The Khronos Group has announced the release of the provisional specifications of the OpenCL 3.0 standard. This is the industrial specification to perform calculations using different hardware components – CPU, GPU, accelerators, FPGA, DSP, etc.

The Khronos Group, the industrial consortium that deals with creating interoperable standards, has announced the publication of the provisional specifications of OpenCL 3.0. The material is available on GitHub, for the developer community to make contributions before specifications and compliance tests are finalized.
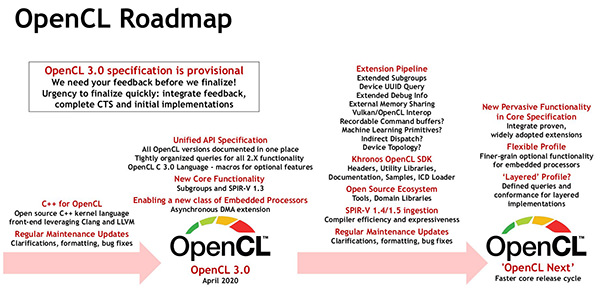
To meet the growing variety of OpenCL devices, the new OpenCL 3.0 makes all functionality beyond version 1.2 optional. All OpenCL 1.2 applications will continue to run smoothly on devices based on the new specification. Neil Trevett, vice president of Nvidia, president of the Khronos Group and part of the working group dedicated to OpenCL, explained that ” although OpenCL 2.X offer important features, OpenCL 1.2 represents the necessary basis for all suppliers and markets “.

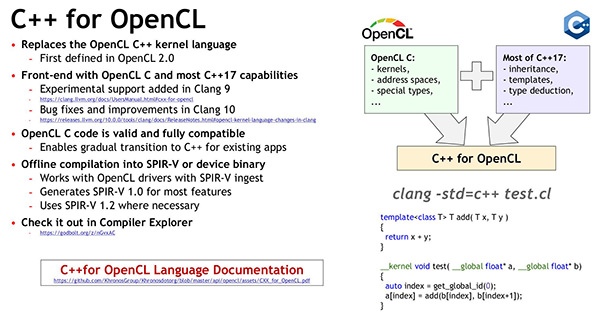
As regards the development of the C++ kernel, the OpenCL Working Group has moved from the OpenCL C++ language defined with OpenCL 2.2 to the community open-source project ” C++ for OpenCL ” supported by Clang. ” C++ for OpenCL provides compatibility with OpenCL C, allows developers to use the C++ 17 features in OpenCL kernels, and is compatible with any OpenCL 2.X or OpenCL 3.0 implementation that supports SPIR-V integration. ”
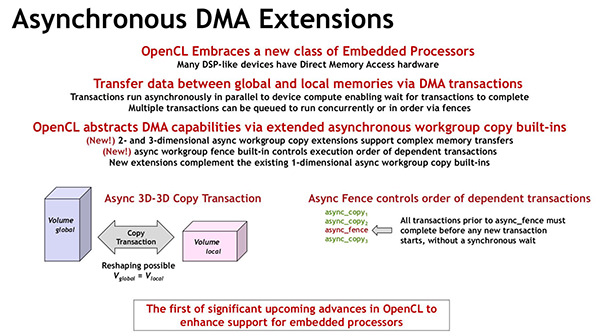
Together with the OpenCL 3.0 specification, the Khronos Group has released the Extended Asynchronous Copy and Asynchronous Work Group Copy Fence extensions to allow efficient and orderly DMA transactions. ” These extensions are the first major innovations in OpenCL to improve support for embedded processors, ” underlines the consortium.
The goal is to further extend the reach of OpenCL beyond CPU and GPU, allowing for heterogeneous calculation on platforms also equipped with FPGAs, DSPs, and accelerators of various types.